
Introduction :
Bonjour à toutes et à tous. Nous sommes Louis et Noah, deux étudiants en deuxième année de PEIP. Dans cet article nous allons vous présenter notre projet qui est le fruit de plus d’une centaine d’heures de travail, Fault Predictor Pro 2024.
Qu’est-ce que Fault Predictor Pro 2024 ?
Notre projet est un logiciel windows qui utilise des algorithmes de machine learning pour prédire de potentielles pannes de panneaux solaires et d’éoliennes. L’intérêt de la prédiction de panne est que cela permet de réduire les coûts d’entretien. En effet, en agissant sur une machine avant que la panne n’apparaisse, on peut limiter le temps d’arrêt de l’appareil et éviter les éventuelles pannes en série.
Le fonctionnement du logiciel est assez simple :
1- Récupérer des données enregistrées par les capteurs de ces appareils dans un grand fichier
2- Importer ce fichier dans notre logiciel
3- Modifier et sélectionner les données pertinentes pour pouvoir les analyser
4- Prédire de futures pannes avec les données actuelles.
Ce qui nous a poussé à choisir ce projet est qu’il s’agit d’un sujet à l’intersection entre l’informatique et les mathématiques, de plus, la popularisation de ces technologies a attiré notre curiosité avec l’envie de mieux comprendre leur fonctionnement. Une autre raison du choix de ce projet est le côté applicatif, il répond à un besoin concret dans les énergies renouvelables.
Les enjeux lors de la création de ce projet étaient multiples : choisir les technologies nous permettant de créer le logiciel, apprendre à les utiliser, concevoir une interface utilisateur efficace, et enfin comprendre le traitement des données et le fonctionnement des algorithmes de machine learning.
1). Le choix des technologies
Nous n’avions qu’une seule contrainte imposée, le logiciel devait être intégralement écrit en langage python. Ce qui s’est avéré être une chance parce qu’en plus d’être un des langages de programmation les plus simples, nous étions familiers avec celui-ci.
Il nous restait alors à choisir les bibliothèques python nous permettant de créer le programme. Pour l’interface utilisateur nous avions le choix entre deux bibliothèques : Tkinter et PyQt. Nous nous sommes tournés vers PyQt qui offre plus de fonctionnalités et de possibilités de personnalisation. Au vu de la richesse de cette bibliothèque nous sommes très satisfaits de ce choix. Nous utilisons également Pandas pour la manipulation des fichiers qui est la référence dans cet usage, de même pour : MatPlotLib qui nous permet de créer des graphiques, Numpy qui permet la modification des données et Sklearn qui nous offre les algorithmes de machine learning.
2). Concevoir une interface utilisateur efficace
Ce projet est l’application en interface utilisateur d’un papier de recherche dont nos deux tuteurs sont à l’origine. Nous devions créer l’interface la plus intuitive et simple possible pour rendre la technologie accessible à tous. En effet notre logiciel, s’il trouve une application industrielle, doit pouvoir être utilisé par des personnes ne connaissant rien à la programmation et au machine learning.
Pour créer une interface intuitive, il faut pouvoir varier les façons d’interagir avec le logiciel. Nous avons mis :
- des boutons
- des curseurs
- des boîtes à choix multiples
- et une zone pour glisser et déposer des fichiers.
Il fallait également rendre lisible le processus de configuration d’un modèle de machine learning. Nous avons alors mis une barre de progression qui affichait l’avancement de l’utilisateur dans la configuration. Il fallait également adopter la même charte graphique sur chacune des pages en conservant le même agencement de page. Nous nous sommes également aperçu que l’utilisateur avait besoin de comprendre ce que faisait le logiciel en arrière plan. Nous avons donc ajouté des barres de chargement pour mieux visualiser la durée des calculs et du texte explicatif apparaît lorsque l’utilisateur survole un bouton avec sa souris.
3). Comprendre le traitement des données et les principes du machine learning
Pour prédire les pannes avec les algorithmes de machine learning, nos données doivent suivre un processus de transformation bien précis. Comme illustré dans le schéma ci-dessous.
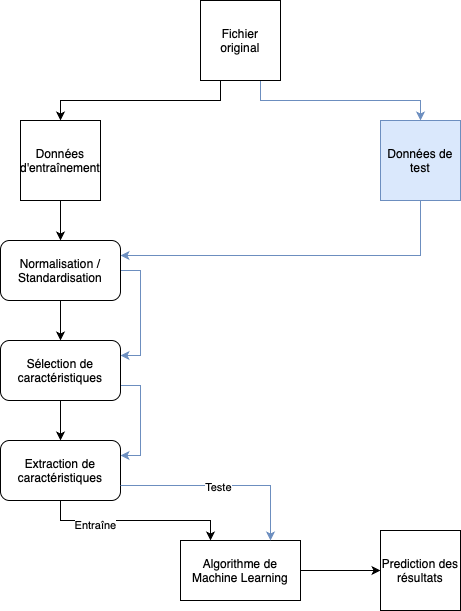
En résumé, les étapes sont les suivantes :
1- Séparer le fichier en deux parties (les données d’entraînement du modèle et les données de test)
2- Normaliser ou standardiser les valeurs des colonnes
3- Supprimer les caractéristiques considérées comme “insignifiantes”
4- “Réduire” la quantité d’information tout en conservant suffisamment de précision
5- Entraîner le modèle avec les données d’entraînement
6- Tester le modèle avec les données de test
Ces étapes de traitement des données peuvent paraître inutiles, mais elles permettent en réalité de gagner beaucoup de précision dans les prédictions. Mais pour créer un modèle fiable, il faut surtout choisir les bons paramètres. C’est pour cela que notre logiciel permet à l’utilisateur de créer autant de modèles qu’il le souhaite pour choisir à la fin le meilleur modèle avec les meilleurs paramètres.
Conclusion :
Nous avons beaucoup appris de ce projet, nous avons amélioré nos compétences en programmation et ce fut l’occasion d’apprendre en un temps restreint les principes du machine learning.
Nous n’aurions pas imaginé arriver à un tel résultat, nous partions de loin et nous n’étions que deux pour un travail complexe.
Ce logiciel est une fierté et nous souhaiterions éventuellement poursuivre l’expérience en contactant des entreprises industrielles qui pourraient être intéressées. La démarche de présentation serait en soi une bonne expérience pour nous et ce travail pourra nous servir de support de communication pour présenter ce dont nous sommes capables
Nous remercions évidemment nos deux tuteurs, Nizar Chatti et Bassel Chokr pour le temps qu’ils nous ont consacré et les connaissances qu’ils nous ont partagé.
Merci pour votre lecture.
Louis Arnaud et Noah Raimbaud