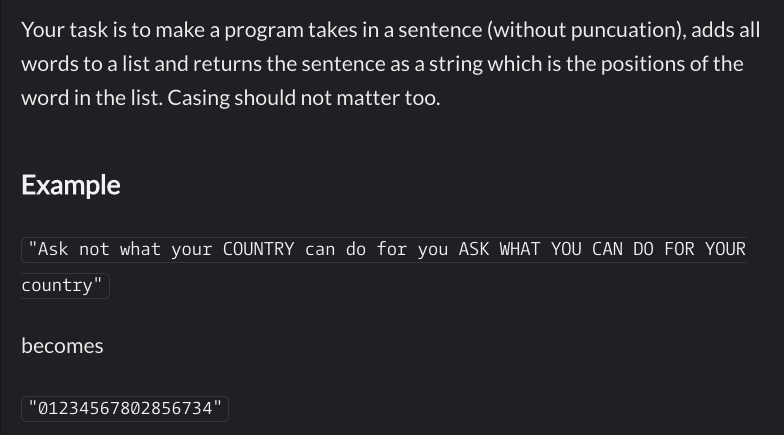
Quelques explications sur la notation polonaise inverse (RPN), utilisée par exemple sur les calculatrices de la marque HP (vidéo sur ma chaine Youtube pour en savoir plus) :

Utilisez ce simulateur pour faire les calculs ci-dessous :
2 ENTER 3 +
Affichage : 5
3 ENTER 4 ENTER 5 * +
Affichage : 23Ces calculatrices utilisent une pile (stack) pour placer (empiler) les valeurs (opérandes) et les calculs sont effectués dès que l’on appuie sur un opérateur (+, -, *, sin, etc.). Pour cela la machine dépile 1 ou plusieurs éléments sur le principe du « dernier arrivé, premier sorti » (LIFO = Last In First Out). Pour des opérateurs dyadiques comme l’addition ou la multiplication, il faut dépiler 2 éléments. Pour un opérateur monadique, comme sinus, on ne dépile qu’une seule valeur.
Reprenons les étapes de l’exemple proposé dans l’énoncé : 5 1 2 + 4 * + 3 –
5 ENTER 1 ENTER 2 // Pile = 5 | 1 | 2 (3 éléments empilés)
+ // Pile = 5 | 3 (calcul 1 + 2 = 3)
4 // Pile = 5 | 3 | 4 (4 empilé)
* // Pile = 5 | 12 (calcul 3 * 4 = 12)
+ // Pile = 17 (calcul 5 + 12 = 17)
3 // Pile = 17 | 3 (3 empilé)
- // Pile = 14 (calcul 17 - 3 = 14) Un des intérêts du RPN est qu’il n’y a pas besoin de parenthèses, d’ailleurs vous n’en trouverez pas sur les anciennes calculatrices HP.
Les piles en python et javascript
Les piles sont simplement des listes où l’on va pouvoir empiler et/ou dépiler des éléments :
En Python
>> pile = [ ] # pile vide
>> pile.append(2) # on empile la valeur 2
>> pile.append(9) # et la valeur 9
>> pile
[2, 9]
>> pile.pop() # On dépile suivant "Last In First Out"
9
>> pile
[2] # Il n'y a plus qu'un seul élément dans la pile
En JavaScript
>> pile = [ ]
>> pile.push(2)
1
>> pile.push(9)
2
>> pile
[2, 9]
>> pile.pop()
9
>> pile
[2]Evaluer une expression en python et javascript
Une première solution (Python et JavaScript) est d’utiliser eval :
>> eval('2 + 3')
5Une autre idée est de voir 2 + 3 comme l’opérateur + appliqué aux opérandes 2 et 3, c’est-à-dire +(2,3). C’est tout simplement la notation f(x,y) utilisée en mathématique.
Voici comment traduire les 4 opérations en JavaScript à l’aide d’un dictionnaire :
>> OPS = {
'+': (x, y) => x + y, '-': (x, y) => x - y,
'*': (x, y) => x * y, '/': (x, y) => x / y
}
>> OPS['+'](2,3)
5Et en Python :
>> OPS = { \
'+': lambda x, y: x + y, '-': lambda x, y: x - y, \
'*': lambda x, y: x * y, '/': lambda x, y: x / y \
}
>> OPS['+'](2,3)
5Idée du programme
Gardons l’exemple : 5 1 2 + 4 * + 3 –
On va séparer (split) les différents éléments de la chaine puis, en partant de la gauche, empiler si c’est un nombre, sinon si c’est un opérateur, dépiler les 2 derniers éléments (les 4 opérateurs +-/* étant tous dyadiques), effectuer le calcul et empiler le résultat.
On empile 5 puis 1 puis 2
'+' étant un opérateur dyadique, on dépile 1 et 2
On effectue le calcul +(1,2) qui donne 3
On empile cette valeur, etc.Python
Vous pouvez tester le programme ici :
def calc(s):
OPS = { \
'+': lambda x, y: x + y, '-': lambda x, y: x - y, \
'*': lambda x, y: x * y, '/': lambda x, y: x / y \
}
pile = [ ] # Pile vide
for v in s.split(): # On parcourt les éléments
if v in OPS: # Est-ce un opérateur ?
b, a = pile.pop(), pile.pop() # on dépile 2 éléments
pile.append(OPS[v](a, b)) # calcul + empiler le résultat
else: # sinon
pile.append(float(v)) # on empile la valeur
return pile.pop() # Contenu de la pile
>> calc('5 1 2 + 4 * + 3 -')
14.0
>> calc('3.5 2.5 +')
6.0JavaScript
Pour récupèrer les clés d’un dictionnaire on peut utiliser la fonction Object.keys. Vous pouvez tester le programme ici :
>> const calc = s =>
{
OPS =
{
'+': (x, y) => x + y, '-': (x, y) => x - y,
'*': (x, y) => x * y, '/': (x, y) => x / y
};
pile = [ ];
for (v of s.split(' '))
{
if (Object.keys(OPS).includes(v)) // includes = contient
{
[b, a] = [pile.pop(), pile.pop()];
pile.push(OPS[v](a, b)) // Ajout du résultat
}
else
{
pile.push(+v) // '+' pour convertir en nombre
}
}
return pile.pop()
}
>> calc('5 1 2 + 4 * + 3 -')
14
>> calc('3.5 2.5 +')
6Version APL
Un peu plus loin avec les réductions
Les calculs s’effectuant de la droite vers la gauche, nous allons déjà retourner le vecteur :
s ← 5 1 2 '+' 4 '×' '+' 3 '-'
⌽s
- 3 +× 4 + 2 1 5Nous avons vu des réductions simples comme +/, ×/ etc :
+/ 1 2 3 4 ⍝ Somme des éléments du vecteur
10
×/ 1 2 3 4 ⍝ Produit des éléments du vecteur
24Mais il est possible de faire des réductions plus complexes, premier exemple :
{⍺,⍺,⍵} / 1 3 4
┌─────────┐
│1 1 3 3 4│
└─────────┘Etape 1 : ⍵ = 4 (terme de droite)
Etape 2 : ⍺ = 3 que l’on ajoute 2 fois à ⍵ (concaténation ⍺,⍺,⍵), ce qui donne ⍵ = 3 3 4
Etape 3 : ⍺ = 1 que l’on ajoute 2 fois à ⍵ = 3 3 4 d’où le 1 1 3 3 4
Autre exemple :
{⍺, ⌽⍵} / 1 2 3 4
┌───────┐
│1 3 4 2│
└───────┘Etape 1 : ⍵ = 4 (terme de droite)
Etape 2 : Ajouter ⍺ = 3 et inverser ⍵ = 4, on obtient ⍵ = 3 4
Etape 3 : Ajouter ⍺ = 2 et inverser ⍵ = 3 4, on obtient ⍵ = 2 4 3
Etape 4 : Ajouter ⍺ = 1 et inverser ⍵ = 2 4 3, on obtient ⍵ = 1 3 4 2
évaluation d’une expression
Voici comment on peut transformer un vecteur à 3 éléments, par exemple ‘+’ 4 2 en ‘4 + 2’ et l’évaluer :
'+' 4 2 [2 1 3] ⍝ Prendre 2e 1er et 3e élément dans cet ordre
4 + 2 ⍝ Le résultat reste un vecteur à 3 éléments
⍕ '+' 4 2 [2 1 3] ⍝ Transformer ce vecteur en chaine avec ⍕
4 + 2
⍎ ⍕ '+' 4 2 [2 1 3] ⍝ Evaluer le résultat avec ⍎
6simulation d’une pile
pile ← 4 6 8 9 ⍝ Une pile de 4 éléments
¯1↑pile ⍝ Récupérer le dernier élément
9
¯1↓pile ⍝ Supprimer le dernier élément
4 6 8
¯2↑pile ⍝ Récupérer les 2 derniers éléments
8 9Programme final
Lien pour tester directement le code ci-dessous :
calc ← {⍺ ∊ '+-×÷' : (¯2↓⍵), ⍎⍕ (⍺,¯2↑⍵)[2 1 3] ⋄ ⍵, ⍺} / ⌽
calc 4 2 '+'
┌─┐
│6│
└─┘
calc 5 1 2 '+' 4 '×' '+' 3 '-'
┌──┐
│14│
└──┘Explications :
Si l’élément ⍺ du vecteur est un opérateur (⍺ ∊ ‘+-×÷’) alors supprimer les 2 derniers éléments de la pile ( ¯2↓⍵ ) et concaténer le calcul (⍎) entre l’opérateur ⍺ et les 2 opérandes au sommet de la pile ( ¯2↑⍵ ) en les mettant dans le bon ordre ([2 1 3]). Sinon, ajouter la valeur ⍺ à la pile ( ⍵,⍺ ).